在 MolmoSpaces 基准上以推理时搜索取得 SOTA¶
作者: Nishanth Kumar · 译者:Jie Wang · 2026年5月8日
原文链接:点击此处
我们最近开发了 TiPToP:一个通用操控系统,先用基础模型做感知,再通过推理时搜索生成轨迹(具体而言即任务与运动规划,TAMP)。系统输入自然语言与图像,输出试图完成指令的轨迹——其输入输出规格与视觉–语言–动作模型(VLAs)、世界动作模型(WAMs)等端到端机器人基础模型相当。
在我们发布系统的同期,涌现出多个旨在支持大规模跨方法比较的基准测试。其中之一是 MolmoSpaces,一个基于仿真的基准测试,其排行榜涵盖了大多数最先进的 VLAs、WAMs 及相关操控方法。我们认为,让TiPToP再他上面试试看会很有趣
TiPToP 在 MolmoSpaces 上取得 46.1%——超越了所有未在 MolmoBot 数据上训练的方法,成绩几乎是次佳结果(MolmoAct2-DROID)的两倍。这是在 9 个任务上、每任务各 1000 个回合上跑出的结果,且未改动底层实现(额外工作仅为对接 MolmoSpaces API 的集成层)。值得注意的是,TiPToP 不依赖机器人数据,未针对该基准调优,可跨任务与形态泛化,且是排行榜上唯一采用推理时搜索的方法。
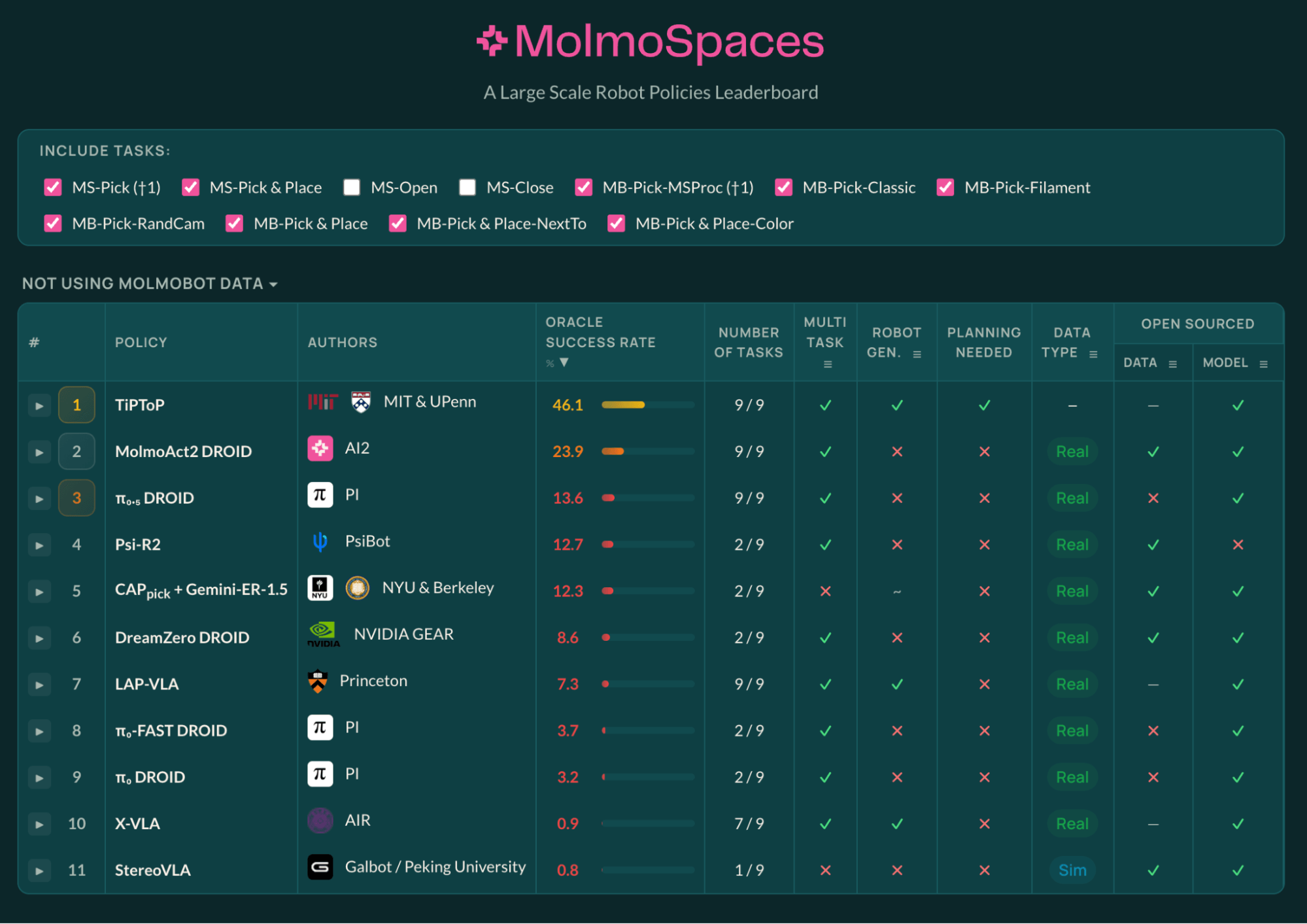
图 1:截至 2026 年 5 月 7 日,MolmoSpaces 全部 9 个任务的基准结果(不含 MS-Open 与 MS-Close)。¶
结果中还有若干亮点(可在此查看排行榜并探索更多信息):
在「未使用 MolmoBot 数据」榜单的「全任务综合」(All Combined)类目上排名第一。 TiPToP 综合得分 34.7%,领先 MolmoAct2(25.0%)、π₀.₅-DROID(17.8%)、LAP-VLA(10.1%);这是在 MS-Open 与 MS-Close 任务变体上我们的方法未能运行(故成功率为 0%)的前提下取得的。
在 Place-NextTo 任务上排名第一,超过榜上所有策略——包括在 MolmoBot 数据上训练的策略。 TiPToP 达 38.0%,领先 π₀.₅-MolmoBot-FT(28.7%)、MolmoBot-f3(28.4%)与 MolmoBot 本体(26.4%)。我们推测这得益于我们的方法在处理复杂自然语言与空间关系上的能力。
失败分析¶
由于 TiPToP 是模块化系统,我们能够对 MolmoSpaces 的结果做对学习型策略往往很难的一件事:把每个失败回合追溯到具体肇因模块。我们对 9000 次试验逐一追溯并标注;下面的桑基图概括了结论。
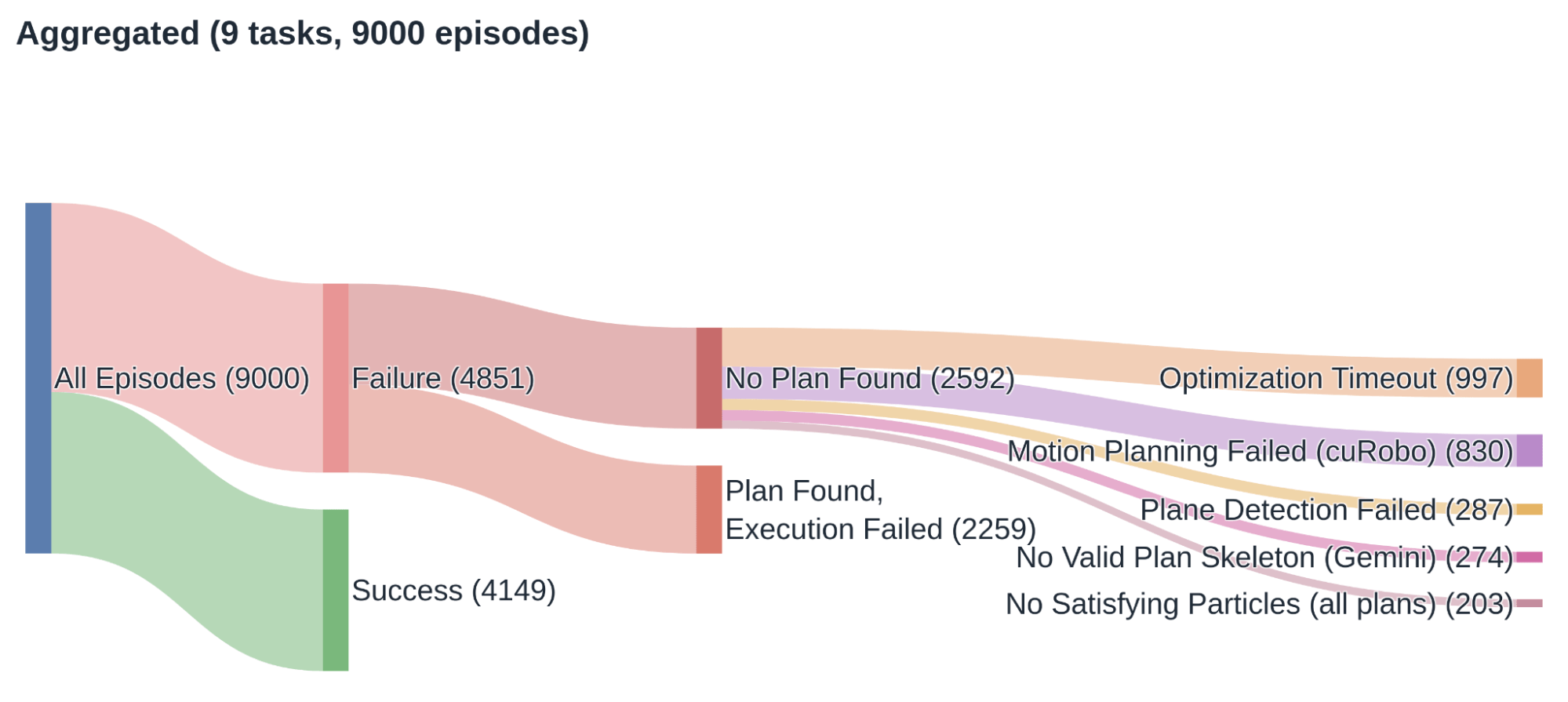
主要发现:
执行失败在总体中占了可观比例。 25.1% 的试验属于:TiPToP 已找到规划(系统认为能解决任务),但开环执行仍失败。执行失败多与运动中物体从夹爪滑脱、或抓取不佳导致未能拾起有关。
规划失败的大多数来自优化与运动规划。 优化超时(占「未找到规划」回合的 31.0%)与 cuRobo 运动规划失败(25.8%)合计约占规划失败的约 57%。我们怀疑主因在于:(1)用分割点云的凸包近似物体几何;(2)在 cuRobo 中用有向包围盒表示物体而非更精确的碰撞表示。
我们相信有几条清晰路径可缓解这些问题、提升性能。例如,我们发现 MolmoSpaces 中我们侧的控制器尚未在闭合夹爪完成后才继续轨迹,这会显著推高滑脱风险;也可在优化与运动规划中使用更精确的物体表征(例如形状补全)来降低规划失败率。
更重要的是,这类改动可在单模块落地,而不必牵动全栈。我们期待若干改进组合起来,能明显提高 TiPToP 在整个基准上的成功率。
总结¶
下面以常见问题(FAQ)的形式,归纳我们从上述结果得出的一些启示。
1. 你们是在主张任务与运动规划(TAMP)优于端到端学习吗?
不是——我们认为我们的发现所指向的结论比简单的”更好”或”更差”要微妙得多。
其一,直白的数据事实是:一个不依赖机器人训练数据、建立在预训练基础模型上的 TAMP 系统,在该基准上胜过了用多得多的数据训练的 VLAs 与 WAMs。出乎意料;我们据此认为模块化与推理时搜索在机器人里能提供强杠杆,值得更多研究与工程投入。
其次,TAMP 与端到端策略的失败和成功模式各有不同。TiPToP 在灵巧操作、杂乱场景以及超出其算子集的任务上表现不佳;而端到端方法则在长时序组合、语义理解和精确空间推理上存在困难。我们认为,仔细比较两者的失败边界,是深入理解机器人操作这一问题更具建设性的方式。
第三,这两种范式并非对立。端到端学习具有反应性,并能随数据改善;搜索与符号结构则提供了长时序推理和处理复杂组合查询的能力。两者都具有真正的价值,如何将它们结合起来,是一个我们认为远比孰优孰劣更有趣的开放问题。
2. TiPToP 难道不是从根本上就需要繁琐的手工工程吗?
确实需要一些手工工程——例如定义符号谓词、算子和采样器——但我们认为这类似于设计神经网络架构,且已有研究表明这些结构也可以从演示数据中学习。在实践中,TiPToP 使用了 11 个谓词和 5 个算子,在 MolmoSpaces 以及我们评估过的所有真实世界任务中无需更改。整个系统由 3 名博士生用约 2.5 个月时间基于现有工具构建,将其移植到 MolmoSpaces 大约花费了一名硕士生一周的时间。我们认为,总体投入与当今训练最先进的 VLA 或 WAM 所需的工作量相当,在许多情况下甚至更少。
3. 你们的系统是否只适用于抓取和放置问题?
不是。我们在论文中展示了可增加新技能(例如擦白板),但需要额外工时定义新的运动原语与符号部件(擦除场景约数小时)。我们估计再用约一周可把能力扩到铰接物体的开合(如抽屉、门)。
4. 这岂不正是「苦涩的教训」(the Bitter Lesson)所反对的方向吗?
我们认为不是。直接引用”苦涩的教训”原文:”突破性进展最终会由一种对立的方法实现,该方法基于通过搜索和学习来扩展计算。”TAMP,特别是 TiPToP,正是基于搜索的,并且在推理时进行扩展。模块化架构还使我们能够随时换入更好的基础模型,因此系统可以从大规模学习模型的进展中获益,而非与之竞争。
5. TiPToP 中的许多想法看起来并不新颖:为什么在此之前无法构建这样的系统?
虽然相近思路的系统早已有之,但至少两件近事改变了局面:(1)用于感知、grounding 与可供性预测的基础模型已极强,可与规划器对接并在真实环境里给出可用性能且仍在变强;(2)规划显著变快——近期 GPU/CPU 与算法并进,搜索与运动规划可以极快运转。
6. 您在论文中强调了系统做出的若干假设和近似(例如用凸包表示物体)。这些限制是根本性的吗?
我们确实做出了若干明确的假设和近似,并已尽力加以说明。这些假设明确了系统将会失败的问题类型(即假设被违反之处),我们认为这是一种优势,因为它使系统更具可解释性。我们认为,尽管存在诸多限制和假设,系统在 MolmoSpaces 基准上仍表现良好,这一点值得关注:这不仅揭示了这些假设对于广义抓取和放置问题的适用性,还提供了一套具体的系统改进方向(即消除这些假设)。我们不认为这些限制是根本性的:针对我们识别出的几乎每一个限制,现有研究都已提出了解决方案。我们相信,通过若干有针对性的改进来解决特定限制,可以非常显著地提升系统性能。
致谢¶
@ryanlindeborg Lindeborg 主导了 TiPToP 与 MolmoSpaces 的集成工作,并收集和分析了相关结果。@WillShenSaysHi 支持了集成工作,协助运行基准实验,并帮助分析了结果。@nishanthkumar23 协助集成并参与分析和呈现结果。@omarrayyann、Maximilian Argus、@wpumacay7567 和 @notmahi 提供了鼓励和宝贵的调试支持,使 TiPToP 得以与 MolmoSpaces 集成并将我们的结果添加到公开排行榜。